Was ist RAID 0? Merkmale, Funktionsweise, Vorteile, Einschränkungen und Einsatzszenarien
-
 Geschrieben von Kees Jan Meerman
Geschrieben von Kees Jan Meerman -
 Aktualisiert am Jun 25, 2026
Aktualisiert am Jun 25, 2026 -
 Min. Lesezeit 4 Min
Min. Lesezeit 4 Min - Teilen
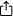
In ihrem Vortrag „A Case for Redundant Arrays of Inexpensive Disks (RAID)”, den sie 1988 auf der SIGMOD-Konferenz hielten, stellten David Patterson, Garth Gibson und Randy Katz eine aufschlussreiche Prämisse vor: RAID 0. Durch die einfache Verteilung von Daten auf kostengünstige PC-Laufwerke ohne Redundanz bewiesen sie, dass es möglich ist, den IO-Durchsatz und die Kapazität mit geringem finanziellen Aufwand zu vervielfachen – vorausgesetzt, man ist bereit, das Risiko einzugehen, bei einem Laufwerksausfall alles zu verlieren.
Was ist RAID 0?
RAID 0 – auch als Striping bekannt – ist die einfachste Array-Organisation. Es handelt sich um RAID, jedoch ohne Redundanz. Zwei oder mehr physische Laufwerke werden als ein einziges logisches Volume behandelt, und jede Datei wird in gleich große Teile oder Stripes unterteilt. Diese Stripes werden in Round-Robin-Reihenfolge auf die Laufwerke geschrieben, sodass alle Spindeln (oder Kanäle im Falle von SSDs) parallel arbeiten.
Da keine zusätzlichen Kopien oder Paritätscodes gespeichert werden, bietet RAID 0 drei wesentliche Merkmale:
- Geschwindigkeit: Die sequentielle Bandbreite und die IOPS (Input/Output Operations per Second) skalieren nahezu linear mit der Anzahl der Laufwerke.
- Volle Kapazität: Sie behalten 100 % des gesamten Laufwerksspeicherplatzes – ohne Overhead.
- Keine Fehlertoleranz: Wenn ein Mitglied ausfällt, bricht der Stripe-Satz zusammen und Sie benötigen professionelle Hilfe, um Daten aus dem RAID 0-Setup wiederherzustellen.
Dieser Kompromiss macht RAID 0 attraktiv für nicht kritische Workloads – Scratch-Rendering, Hochgeschwindigkeits-Capture-Puffer, Gaming-Rigs für Enthusiasten –, bei denen die reine Leistung wichtiger ist als die Haltbarkeit.
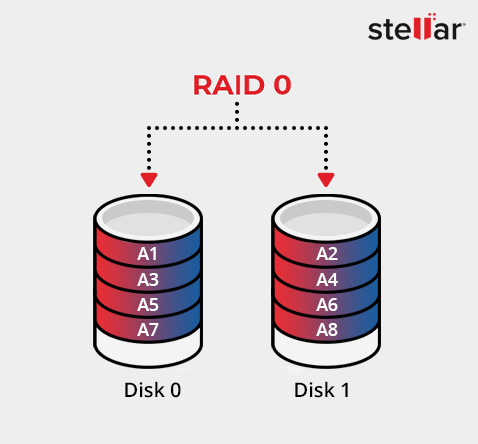
RAID 0 in einem Array, in dem die Daten auf fünf Festplatten verteilt sind
Wie funktioniert RAID 0 oder Striping?
1. Striping-Logik
Der RAID-Controller (oder die Betriebssystemsoftware) wählt eine Blockgröße, beispielsweise 64 KB. Er unterteilt eingehende Schreibvorgänge in Blöcke und weist sie sequenziell den Festplatten zu: Block 0 der Festplatte 0, Block 1 der Festplatte 1, Block 2 der Festplatte 2 usw. Wenn das letzte Laufwerk erreicht ist, beginnt der Vorgang von vorne.
2. Stripe-Zusammensetzung
Eine Gruppe von Blöcken mit dem gleichen logischen Offset bildet einen Stripe. In einem Array mit vier Festplatten könnte die zuerst erstellte Stripe die Blöcke 0–3 enthalten (d. h. einen Block pro Festplatte). Größere Blockgrößen – beispielsweise zwei Blöcke pro Festplatte – führen zu breiteren Stripes, was große sequenzielle Übertragungen begünstigt; kleinere Blöcke verbessern die Parallelität bei gemischten E/A-Operationen.
3. Lese-/Schreibverhalten
Bei sequenziellen E/A-Operationen sendet der Verantwortliche Befehle gleichzeitig an alle Laufwerke im Streifen und nutzt dabei die Bandbreite aller Spindeln auf einmal. Zufällige E/A-Operationen werden so verteilt, dass kein einzelnes Laufwerk zu einem Hotspot wird.
Die Latenz für einen einzelnen 4-KB-Lesevorgang entspricht in etwa der eines einzelnen Laufwerks, aber der Gesamtdurchsatz erreicht N × S für sequentielle und N × R für zufällige Workloads (wobei N die Anzahl der Laufwerke, S die sequentielle Lesegeschwindigkeit in MB/s und R die zufällige Lesegeschwindigkeit in MB/s ist).
4. Ausfallsemantik
Ohne Parität oder Spiegelung hat das Array keine Möglichkeit, verlorene Blöcke zu rekonstruieren; eine ausgefallene Festplatte kann alle Dateien ungültig machen.
Ein funktionierendes Beispiel für RAID 0
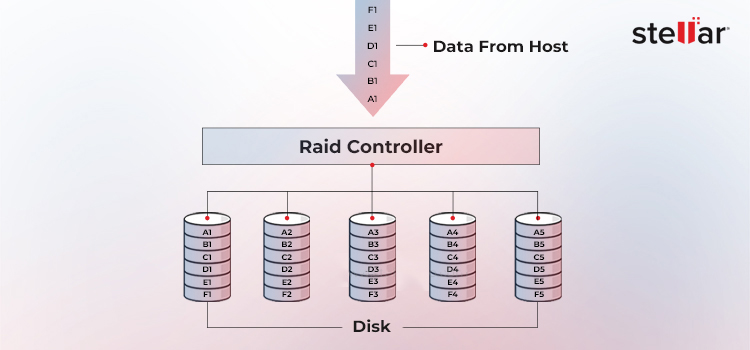
Betrachten Sie diesen Satz als Datenblock: „RAID_0_ist_wirklich,_wirklich_schnell.“
Verteilen wir diesen aus sechs Wörtern bestehenden Satz mit einer Blockgröße von vier Zeichen auf vier Festplatten.
1. Schreibpfad
Wort 1 („RAID“) landet auf Festplatte 0.
Wort 2 („_0_g“) landet auf Festplatte 1, Wort 3 („oes_“) auf Festplatte 2 und Wort 4 („real“) auf Festplatte 3.
Die verantwortliche Person beginnt dann mit dem zweiten Streifen: „ly,_“ → Festplatte 0, „real“ → Festplatte 1, „ly_f“ → Festplatte 2 und „ast.“ → Festplatte 3.
2. Lesepfad
Das sequenzielle Lesen der Aufzeichnung wird von vier Laufwerken gleichzeitig durchgeführt – jedes liefert seinen Teil, während die anderen zum nächsten Block übergehen, wodurch etwa die vierfache Bandbreite eines einzelnen Laufwerks erreicht wird.
3. Ausfallszenario
Wenn Festplatte 2 ausfällt, gehen die Teile „oes_“ und „ly_f“ verloren, wodurch beide Streifen beschädigt werden und der Satz unlesbar wird. Dies ist der Kompromiss bei RAID 0: rasante Geschwindigkeit, aber keine Toleranz gegenüber einer ausgefallenen Festplatte.
RAID 0 – Vorteile und Einschränkungen
RAID 0 ist einfaches Striping ohne Redundanz. Es ist die Grundlage, auf der Patterson, Gibson und Katz in ihrer Veröffentlichung von 1988 fünf verschiedene RAID-Konfigurationen modelliert haben.
- 75 kostengünstige Festplatten haben potenziell die 12-fache I/O-Bandbreite des IBM 3380 und die gleiche Kapazität bei geringerem Stromverbrauch und geringeren Kosten.
| Merkmal | Bedeutung in der Praxis |
|---|---|
| Leistung | Sequentielle Bandbreite ≈ W × (Bandbreite eines einzelnen Laufwerks); IOPS skalieren ähnlich, bis die Controller-Warteschlange oder die PCIe-Lanes gesättigt sind. |
| Kapazität | Summe aller Mitgliedslaufwerke; kein Overhead. |
| Zuverlässigkeit | Mittlere Zeit bis zum Datenverlust (MTTDL) ≈ MTBF / W: Jedes zusätzliche Laufwerk verkürzt die mittlere Zeit bis zum katastrophalen Verlust. Ein RAID 0 mit 20 Laufwerken kann innerhalb von fünf Jahren eine Ausfallwahrscheinlichkeit von ≥ 50 % aufweisen, selbst mit SAS-Laufwerken der Enterprise-Klasse. |
| Datenrettung | Keine – es gibt nichts wiederherzustellen. Backups oder Replikation auf höherer Ebene sind zwingend erforderlich. |
Einsatzszenarien – wo RAID 0 geeignet ist
RAID 0 eignet sich für Szenarien, in denen reine Geschwindigkeit und volle Kapazität wichtiger sind als Fehlertoleranz. In der folgenden Tabelle sind solche Szenarien mit den Gründen aufgeführt, warum RAID 0 in diesen Fällen erfolgreich ist.
| Szenario | Warum RAID 0 attraktiv ist |
|---|---|
| Produktion von Videos oder Bildern mit hoher Bitrate | Umfangreiche sequenzielle Lese-/Schreibvorgänge belasten einzelne Festplatten; Striping bündelt die Bandbreite für flüssige 4K/8K-Zeitleisten und Echtzeit-Effekte. |
| Scratch- oder Render-Caches in VFX/wissenschaftlichen Berechnungen | Datensätze können auf einfache Weise neu generiert werden, sodass der Verlust eines Volumes zwar Zeit kostet, aber keine unersetzbaren Informationen. Parallele Stripes beseitigen Rendering-E/A-Engpässe. |
| Hochgeschwindigkeits-Ingest-Puffer (Laborinstrumente, Kameraaufnahmen) | Kurzfristige Landing Zones erfordern Burst-Schreibvorgänge; nach der Erfassung werden die Dateien in einen geschützten Speicher verschoben. |
| Gaming- oder Benchmark-Rigs für Enthusiasten | Synthetische Tests und Ladebildschirme haben höhere Übertragungsraten; das Risiko ist akzeptabel, da Betriebssystem-/Spiel-Images einfach neu installiert werden können. |
| Temporäre Build- oder Testumgebungen | Kontinuierliche Integrationspipelines kompilieren Artefakte, die bei jedem Durchlauf neu erstellt werden, wobei die Kompilierungsgeschwindigkeit Vorrang vor der Persistenz hat. |
Bereitstellungsszenarien – in denen RAID 0 vermieden werden sollte
Trotz der Verlockung der Geschwindigkeit ist RAID 0 die schlechteste Wahl für alle Workloads, die keinen Datenverlust oder lange Wiederherstellungszeiten tolerieren können. Betrachten Sie diese Anwendungsfälle.
- Geschäftskritische Datenbanken und Transaktionssysteme: Der Ausfall einer einzigen Festplatte zerstört alle Tabellen; stattdessen sind gespiegelte (RAID 1/10) oder Paritäts-Arrays die Norm.
- Unternehmensdateifreigaben, Archivmedien oder Nearline-Backup-Sets: Die Kapazität ist groß, die Daten sind einzigartig und die Wiederherstellungsfenster müssen vorhersehbar sein. Stattdessen bieten RAID 5/6 oder Erasure Coding Schutz mit weitaus geringerem Risiko.
- Workloads mit gemischten zufälligen E/A-Operationen, die für die Datenrettung nicht unterbrochen werden können: Die Leistung ist gering, aber die Datenrettung nach einem Ausfall erfordert eine vollständige Wiederherstellung aus dem Backup.
- Jede Umgebung ohne eine robuste, automatisierte Backup-Strategie: Striping vervielfacht das Risiko eines Volumenverlusts: n Laufwerke → n-fache Ausfallwahrscheinlichkeit. Ein RAID 0 mit zwei Festplatten verdoppelt das Risiko bereits.
RAID 0 bietet Geschwindigkeit auf Kosten der Sicherheit. Verwenden Sie es nur, wenn die Workload entbehrlich oder anderweitig geschützt ist; andernfalls wählen Sie ein RAID-Level (oder eine Cloud-Ebene), das Ihren Anforderungen an die Haltbarkeit entspricht.
RAID 0 hat daher zwei Seiten: Es hat die Leistung von RAID unter Beweis gestellt und jeden Speicherarchitekten daran erinnert, dass Geschwindigkeit ohne Dauerhaftigkeit nur für entbehrliche Daten funktioniert.
Über RAID 0 hinaus
RAID 0 hat bewiesen, dass Striping massive Geschwindigkeitssteigerungen erzielen kann – aber es hatte auch einen entscheidenden Nachteil: keinen Schutz vor Laufwerksausfällen. Selbst der Ausfall eines einzigen Laufwerks würde das gesamte Array zerstören. Für den praktischen Einsatz, insbesondere in Unternehmensumgebungen, in denen Datenverluste inakzeptabel sind, reicht RAID 0 allein nicht aus.
Die Forscher in Berkeley haben dies von Anfang an erkannt. Sie schlugen eine ganze Reihe von RAID-Levels vor, von denen jedes eine nützliche Kombination aus Geschwindigkeit, Kapazität und Fehlertoleranz darstellte. Im nächsten Leitfaden werden wir uns mit RAID 1 befassen, das sich auf Datensicherheit durch Spiegelung konzentriert.
Möchten Sie mehr über verwandte Speicherprobleme und professionelle Strategien zur Vermeidung von Datenverlust erfahren? Dann entdecken Sie auch unsere zusätzlichen Leitfäden unten.


Über den Autor



