Was ist RAID? Ursprünge, Erklärung, Bausteine und Konfigurationen
-
 Geschrieben von Kees Jan Meerman
Geschrieben von Kees Jan Meerman -
 Aktualisiert am Mar 03, 2026
Aktualisiert am Mar 03, 2026 -
 Min. Lesezeit 4 Min
Min. Lesezeit 4 Min - Teilen
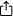
Eine kurze Geschichte von RAID
Bevor moderne Speicher-Arrays und Cloud-Laufwerke zu alltäglichen Werkzeugen wurden, standen Unternehmen vor einer grundlegenden Herausforderung: Wie lassen sich wachsende Datenmengen zuverlässig und kostengünstig speichern?
Speichersysteme mussten mit den rasanten Fortschritten bei Prozessoren und immer anspruchsvolleren Geschäftsanwendungen Schritt halten, hatten jedoch Schwierigkeiten damit.
Mitte der 1980er Jahre waren alle ernstzunehmenden Rechenzentren noch auf einzelne große, teure Laufwerke (SLEDs) angewiesen.
- Das Flaggschiffprodukt von IBM, das 3380-Gehäuse, fasste etwa 2,52 GB Daten, erreichte eine Übertragungsgeschwindigkeit von 3 MB/s, hatte eine durchschnittliche Suchzeit von 16 ms und kostete zwischen 81.000 und 142.000 Pfund – zuzüglich eines Kubikmeters Stellfläche und einem Kilowatt Strom.

- Kleinere Computer schnitten nicht besser ab: Die erste PC-Festplatte, die 5,25-Zoll-ST-506 von Shugart Technology (heute Seagate), hatte eine Kapazität von nur 5 MB und kostete 1.500 £ – umgerechnet 300 £ pro MB.

Gleichzeitig galt das Moore'sche Gesetz für CPUs und immer kostengünstigere DRAMs, deren Geschwindigkeit oder Kapazität sich alle 18 bis 24 Monate verdoppelte, weitgehend unverändert. Dies bedeutete, dass Transaktionsverarbeitung, SQL-Datenbanken und neue Client-Server-Anwendungen weitaus mehr winzige zufällige E/A-Operationen durchführten, als eine einzelne Spindel bewältigen konnte.
Forscher der UC Berkeley – David Patterson, Garth Gibson und Randy Katz – quantifizierten die Lücke: Die Leistung der Prozessoren stieg um 40 % pro Jahr, während sich die mechanische Latenz einer High-End-Festplatte um kaum 7 % pro Jahr verbesserte.
Die Folge war eine drohende „E/A-Krise“: CPUs kamen zum Stillstand, Batch-Fenster überschritten Zeitrahmen, und Unternehmen waren gezwungen, kritische Tabellen auf Hunderte von SLEDs zu verteilen.
Diese schnelle und vorübergehende Lösung verursachte neue Probleme.
- Die Kosten stiegen linear mit jeder zusätzlichen SLED.
- Die Verfügbarkeit sank sogar, da mehr Spindeln auch mehr Fehlerquellen bedeuteten.
- Die Betreiber kämpften einen aussichtslosen Kampf gegen Hitze, Stromverbrauch und Platzmangel.
Was die Branche dringend benötigte, war Durchsatz und Kapazität auf Mainframe-Niveau, jedoch zu PC-Preisen – ohne Kompromisse bei der Zuverlässigkeit.
Genau diese Einschränkungen inspirierten die Speicherforschungsgemeinschaft in den 1980er Jahren.
RAID: Ursprung und Definition
Ende 1987 stellten Patterson, Gibson und Katz in einem Labor der UC Berkeley einen Klapptisch mit zehn 100 MB Conner CP-3100 PC-Laufwerken auf, die an einen Standard-SCSI-Controller angeschlossen waren.

Sie untersuchten eine Frage: Könnte eine Reihe kostengünstiger PC-Festplatten die damals führende Mainframe-Arbeitsmaschine, den IBM 3380, übertreffen?
Ihre 1988 in SIGMOD veröffentlichte Studie „A Case for Redundant Arrays of Inexpensive Disks (RAID)” lieferte die harten Fakten.
| Laufwerk (1987) | Kapazität | Übertragungsrate | Preis/MB | Leistung | Speicherkapazität |
|---|---|---|---|---|---|
| IBM 3380 AK4 | 7500 MB | ≈ 3 MB/s | 18 | 6,6 kW | 24 ft |
| Fujitsu „Super Eagle” | 600 MB | ≈ 2,5 MB/s | 20–17 | 640 |
3,4 |
| Conner CP-3100 | 1000 MB | ≈ 1 MB/s | 11 | 1 | 0,03 ft |
Anschließend modellierten sie ein RAID-Level-5-Array, bestehend aus 100 dieser Conner-Laufwerke (10 Daten + 2 Parität pro Gruppe).
Das Ergebnis:
- Ungefähr fünfmal höherer I/O-Durchsatz, höhere Leistung und Platzersparnis im Vergleich zum IBM 3380
- Reduzierung der Kosten pro Gigabyte um zwei Größenordnungen
- Erhöhte berechnete Zuverlässigkeit dank Paritäts- und Hot-Spare-Datenrettung
Mit anderen Worten: Ein Array im Wert von 11.000 £ erreichte – und übertraf oft sogar – den SLED von 100.000 £ in allen wichtigen Leistungsindikatoren.
Diese tabellarische Darstellung verwandelte RAID von einer Idee in die Realität und läutete den Beginn des Array-Technologiezeitalters ein.
Was bedeutet der Name „Redundant Array of Independent Disks“?
| Wort | Warum es wichtig ist |
|---|---|
| Redundant | Zusätzliche Informationen (vollständige Kopien oder Paritätscodes) werden gespeichert, damit logische Daten nach einem Laufwerksausfall online bleiben. |
| Array | Viele physische Laufwerke werden in einem logischen Adressraum virtualisiert; der Manager weist den Laufwerks-/Sektorpositionen Host-Blocknummern zu, ordnet die E/A-Vorgänge und koordiniert die Datenrettung. |
| Unabhängig (ursprünglich „kostengünstig”) | Standard-Festplatten fallen unabhängig voneinander aus und sind pro GB weitaus kostengünstiger als ein monolithisches SLED. Der RAID-Controller gleicht diese höhere Ausfallrate aus und gewährleistet eine höhere MTTDL (Mean Time to Data Loss) für das System. |
| Festplatten | Das Schema wurde für rotierende Festplatten entwickelt, kann aber auch auf SSDs und andere Laufwerke angewendet werden. |
Ein RAID-Set ist daher eine einzelne virtuelle Festplatte, die dem Host präsentiert wird und aus einer Gruppe kostengünstiger, ausfallanfälliger Laufwerke mit ausreichender Redundanzlogik besteht, um die Datenintegrität zu gewährleisten und eine höhere Gesamtleistung zu erzielen.
Bevor wir uns mit den einzelnen RAID-Levels befassen, benötigen wir drei technische Bausteine – Striping, Spiegelung und Parität – sowie einige grundlegende Begriffe.
- I/O (Input/Output): Jede vom Host ausgegebene Lese- oder Schreibanforderung.
- Host: Der Server oder die Einheit, die für das Versenden von Blockanforderungen über SAS, SATA, NVMe oder FC verantwortlich ist.
- Block (Sektor): Die atomare Einheit (512 B–4 KiB), in der Festplatten Daten speichern und RAID-Algorithmen die Parität berechnen.
Mit diesem Vokabular können wir uns nun ansehen, wie Striping die E/A beschleunigt, wie Spiegelung sofortige Redundanz bietet und wie Parität es uns ermöglicht, verlorene Daten mithilfe eleganter XOR-Mathematik wiederherzustellen.
Die drei Bausteine von RAID – Striping, Spiegelung und Parität
Striping (Leistung und Skalierbarkeit)
Striping ist eine Technik, bei der Daten auf mehrere Laufwerke verteilt werden, damit diese parallel arbeiten können. Alle Lese-/Schreibköpfe arbeiten gleichzeitig auf den entsprechenden Festplatten, sodass mehr Daten in kürzerer Zeit verarbeitet werden können. Dies erhöht die Leistung im Vergleich zu einer einzelnen Festplatte erheblich.
Das folgende Diagramm zeigt, wie Striping in einem Satz von W-Laufwerken funktioniert. Ein Streifen besteht aus N zusammenhängenden Blöcken auf einem Laufwerk; ein Streifen ist der Satz ausgerichteter Streifen, der sich über W-Laufwerke erstreckt (die Streifenbreite).
Stripe-Größe = Strip-Größe × Stripe-Breite.
Die Wahl der Streifengröße ist ausschließlich eine Frage der Optimierung der Arbeitslast. Sie kann für OLTP (Online-Transaktionsverarbeitung) klein (16–64 KiB) oder für Videostreams groß (256 KiB–1 MiB) sein.
Lorem ipsum dolor sit amet, consectetur adipisicing elit. Porro labore architecto fuga tempore omnis aliquid, rerum numquam deleniti ipsam earum velit aliquam deserunt, molestiae officiis mollitia accusantium suscipit fugiat esse magnam eaque cumque, iste corrupti magni? Illo dicta saepe, maiores fugit aliquid consequuntur aut, rem ex iusto dolorem molestias obcaecati eveniet vel voluptatibus recusandae illum, voluptatem! Odit est possimus nesciunt.
Durch die parallele Verarbeitung jeder E/A-Anforderung auf mehreren Festplatten skaliert die sequenzielle Bandbreite nahezu linear mit W, bis der Verantwortliche oder der Bus vollständig ausgelastet ist.
Die RAID-Konfiguration mit reinem Striping (d. h. ohne Spiegelung) ist RAID 0, das keine Redundanz bietet – wenn ein Mitglied ausfällt, ist das gesamte Array verloren.
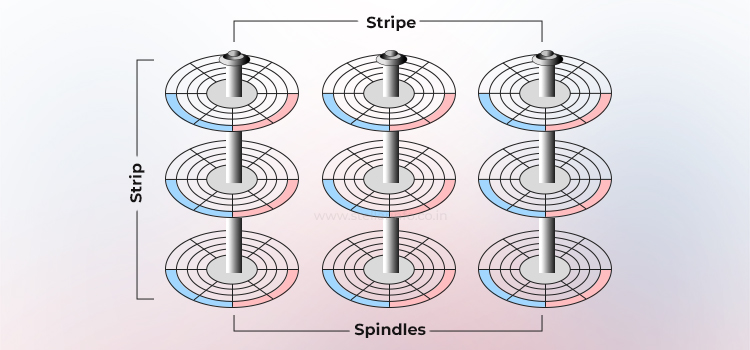
Spiegelung (sofortige Redundanz)
Spiegelung ist eine Technik, bei der dieselben Daten auf zwei verschiedenen Festplattenlaufwerken gespeichert werden. Wenn ein Festplattenlaufwerk ausfällt, bleiben die Daten auf der intakten Festplatte vollständig erhalten. Der Verantwortliche bedient die Datenanforderungen des Hosts ohne Unterbrechung über das intakte Mitglied des gespiegelten Paares weiter.
Wenn die ausgefallene Festplatte durch eine neue ersetzt wird, kopiert die zuständige Stelle automatisch die Daten von der intakten Festplatte auf die neue Festplatte – ein Vorgang, der für den Host transparent ist.
In einer gespiegelten RAID-Konfiguration (RAID 1) wird jeder Schreibvorgang an mindestens zwei Laufwerke versendet. Dadurch entstehen doppelte Datensätze, die als Sub-Mirrors bezeichnet werden. Die verantwortliche Partei kann Lesevorgänge von dem Sub-Mirror ausführen, der am wenigsten ausgelastet ist.
Betriebssysteme für Unternehmen und HBAs (Host-Bus-Adapter) bieten sogar Round-Robin- oder geometrische Lesepolicies, um die Last auszugleichen und die Suchzeit zu reduzieren.
Obwohl die Spiegelung eine geringe Latenz für Schreibbefehle mit sich bringt (sie müssen zweimal ausgeführt werden) und die Kapazitätseffizienz bei 50 % liegt, überwiegen die Vorteile: Im Falle eines Laufwerksausfalls ist die Datenrettung trivial – eine einfache Kopie vom intakten Mitglied auf ein Ersatzlaufwerk.
Parität (mathematisch basierte Redundanz)
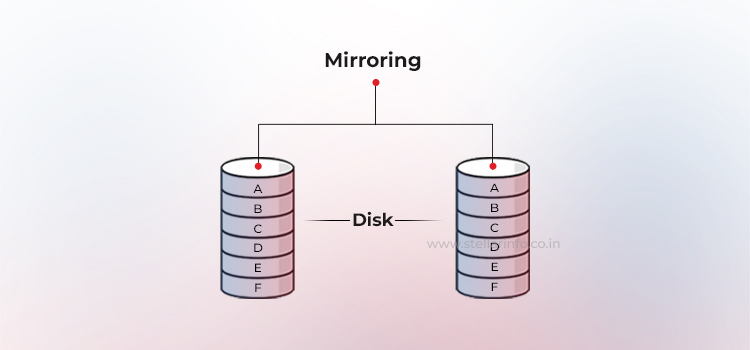
Parität ist eine Methode zum Schutz gestripter Daten vor Festplattenausfällen, ohne die vollen Kosten einer Spiegelung zu verursachen. Anstatt alle Daten zu duplizieren, verwenden RAID-Arrays eine zusätzliche Festplatte (oder verteilten Speicherplatz) zur Speicherung der Parität – einer mathematischen Zusammenfassung der Daten, mit der das System verlorene Informationen rekonstruieren kann.
Diese Parität wird vom RAID-Verantwortlichen mithilfe einer bitweisen XOR-Operation über alle Datenblöcke in einem Stripe berechnet. Wenn ein Laufwerk ausfällt, kann der fehlende Block sofort wiederhergestellt werden, indem die restlichen Daten mit der gespeicherten Parität XOR-verknüpft werden.
Betrachten Sie beispielsweise drei Bits: A, B und C, wobei A die aus B und C generierte Parität ist. So funktioniert XOR:
| A | C | A = B ⊕ C |
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Wenn Sie A und entweder B oder C kennen, können Sie das dritte Element immer wiederherstellen. Dies ist das Paritätsprinzip, das RAID zur Wiederherstellung fehlender Datenblöcke verwendet.
Paritätsinformationen können auf einer dedizierten Festplatte (RAID 4) gespeichert oder auf alle Mitglieder verteilt werden (RAID 5). RAID 6 geht noch einen Schritt weiter und fügt einen zweiten Paritätsblock hinzu, der eine Datenrettung bei zwei gleichzeitigen Ausfällen ermöglicht. Der Nachteil ist ein geringer Schreib-Overhead: Bei jeder Aktualisierung werden sowohl die Originaldaten als auch die Parität geändert, was zusätzliche Lese-, Änderungs- und Schreibzyklen erfordert, die sich auf die Leistung auswirken.
RAID ist ein Framework – jede Stufe löst ein anderes Problem
Die Veröffentlichung aus Berkeley von 1988 hat also mehr als nur ein Akronym geprägt – sie hat ein Framework für die Skalierung von Speichersystemen entlang dreier Achsen definiert: Leistung, Kapazitäts effizienz und Fehlertoleranz.
- Reines Striping ohne Redundanz wurde zu RAID 0.
- Durch Hinzufügen einer vollständigen Duplizierung entsteht RAID 1, das die Verfügbarkeit gegenüber nutzbaren Terabytes priorisiert.
- Kombiniert man Striping mit mathematischer Parität, erhält man RAID 5- und 6-Konfigurationen, die etwas Schreibgeschwindigkeit opfern, um den Ausfall eines oder sogar zweier Laufwerke zu überstehen.
Jede Konfiguration ist einfach ein anderer Punkt in dem Raum, der in dem SIGMOD-Papier von 1988 aufgezeichnet wurde.
Read further articles to deepen your knowledge of RAID and data recovery:


Über den Autor



